Most research papers focus on one
machine learning
(ML) model for a specific task, analyze the accuracy achieved and the efficacy of the processing
architecture in executing that model, but there are many additional considerations when deploying
real solutions in the field. Technologies including the dedicated neural network processing unit
(NPU) supplying 2.3 TOPS of acceleration in the NXP i.MX 8M Plus applications processor, provide
choice and flexibility to customers for a wide range of applications using machine learning and
vision. Arcturus Networks’ development of an application to monitor ATM locations for a bank
demonstrates the versatility and technology needed in secure edge applications.
We invited our colleague, David Steele, Director of Innovation for Arcturus to share details on
the project and their development approach:
The Arcturus team recently engaged on a project with a bank to monitor their ATM locations. The
bank wanted to prevent crowding in ATM areas and restrict access to people wearing masks. This
application is an ideal example of edge AI because the edge is where the data source is and where
the local actions need to take place. It also presents some interesting challenges.
Analysis of sample data revealed that acute camera angles common in small enclosed ATM spaces
caused a loss of detection confidence as perspectives became more top down (Figure 1).

Figure 1 – Acute / High Angle Perspective Causing Loss of Detection Confidence
In addition, the application needed to distinguish between people wearing masks and those not.
This is not as trivial as simply improving the detection of an existing class to include people
wearing masks. The appearance of helmets or other face coverings can also be considered personal
protective equipment (PPE) (Figure 2), thus multiple new detection classes are required.
Furthermore, the bank wanted to extend analysis to detect suspicious behaviour, including
loitering.

Figure 2 - Helmet and Mask Classes Detected Separately
To improve detection confidence and add new classes to the network requires the use of domain
specific data and model fine-tuning or retraining. This process is done off-line from the edge
with results measured against a ground truth data set. This process is iterative, but by using
domain specific data the results offer critical model improvement.
Once the model is trained, fine-tuned and validated, the model can be moved to the i.MX 8M Plus
edge hardware which has a dedicated 2.3 TOPs NPU. To make efficient use of the NPU, the model
needs to be converted from its native 32-bit floating point (FP32) precision to 8-bit integer
(INT8). This quantization process can cause some accuracy loss, requiring revalidation.
A runtime inference engine is required to load the model into the i.MX 8M Plus. NXP eIQ® machine
learning (ML) software development environment provides ported and validated versions of Arm® NN
and TensorFlow Lite inference engines; However, edge runtime versions do not support all layers
required by all types of networks –newer models and less popular models tend to be less broadly
supported.
To help reduce the time it takes to train and deploy edge AI systems, Arcturus provides a
catalogue containing prebuilt models using different precisions. These models are pre-validated to
support all the major edge runtimes; Arm NN, TensorFlow Lite and TensorRT with CPU, GPU and NPU
support. Tooling is available to train or fine-tune models along with dataset curation, image
scraping and augmentation. The results of this combination of optimized runtime, quantized model
and NPU hardware can offer a 40x (Figure 3) performance improvement when compared with other
publicly available systems running the same model.

Figure 3 - Optimized Performance Using Edge Runtimes, Quantization and NPU Hardware
Once the model is running efficiently at the edge, the output needs to be analyzed. If the
analysis were being performed on a still image, a binary classification could determine if PPE was
present or not. With live video this becomes more difficult as partial occlusions and body pose
will cause variability in detection results. To improve accuracy, a more intelligent determination
needs to be made over multiple frames. To do this requires tracking each unique person to obtain a
larger sample. Motion model tracking is a simple, light-weight approach suitable for this task,
however, it relies on continuous detections. Occlusions, obstructions or a person leaving and
re-entering the field of view will cause track loss. Thus, to detect loitering requires a more
robust tracking approach capable of reidentification, irrespective of time or space.
Reidentification is accomplished by using a network that generates a visual appearance embedding.
This workflow requires that the object detection network pass localization, frame and class
information to the embedding network (Figure 4). Synchronization between networks and the data
stream is critical as any time-skew may cause an incorrect reference. Output is compared with
motion model data and an identity assignment determined. Embeddings can be shared across
multiple-camera systems, they can be used for archival searches, to create active watch lists or
even post-processed further by applying clustering techniques.
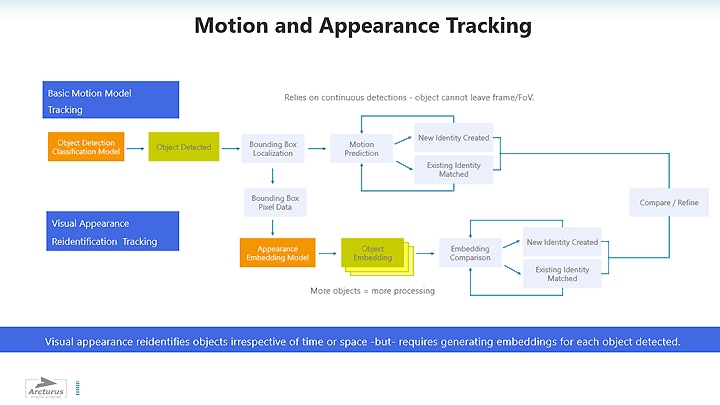
Figure 4 - Comparing Motion and Visual Appearance Tracking Workflows
Adding a visual appearance embedding to motion model tracking requires the processing of each
detected object. Therefore, more objects equals a need for more processing. In our application,
the number of people is inherently bound by the physical space available. However, with a larger
field of view, this could present a significant bottleneck.
To address this, Arcturus has developed a vision pipeline architecture where different stages of
processing are represented by nodes e.g., inference, algorithms, data, or external services. Each
node acts like a microservice and is interconnected via a tightly synchronized serialized data
stream. Together, these nodes create a complete vision pipeline from image acquisition through to
local actions. For basic applications, pipeline nodes can run on the same physical resource. More
complex pipelines can have nodes distributed across hardware, either CPUs, GPUs, NPUs – or even
the cloud. Pipelines are orchestrated at runtime making them infinitely flexible and scalable, and
helping to futureproof edge investment. Each node is discreetly containerized, making it simple to
replace one part of the system e.g., an inference model can be updated without disrupting the rest
of the system, even if model timing changes.
This pipeline architecture is the core of the Arcturus Brinq Edge Creator SDK, making it possible
to scale AI performance beyond one physical processor. For example, one i.MX 8M Plus can perform
detection while a second i.MX 8M Plus generates embeddings. These devices can be interconnected
easily using a network fabric across one of the two dedicated Ethernet MACs on each of the
processors. To take this one step further, this software can be combined with the Arcturus Atlas
hardware platform that can scale up to 187fps (figure 5) using multiple hardware configurations
including i.MX 8M Plus.
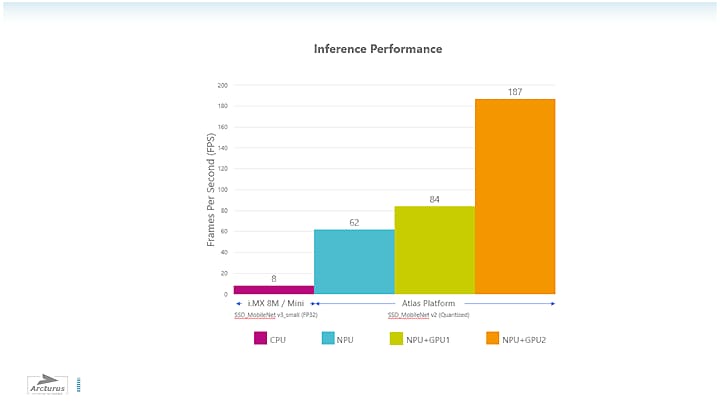
Figure 5 – Arcturus Atlas Hardware Platform Performance Using NXP i.MX 8M Plus with Acceleration
Options
In summary, when it comes to the overall design of an application, consider that your requirements
may evolve. Class-based detection may need to be augmented with algorithms or other networks.
Futureproofing your edge AI will require building on an extensible pipeline architecture, such as
the Brinq Edge Creator SDK and leveraging scalable hardware performance like the Atlas platform
enabled by the NXP i.MX 8M Plus processor with NPU accelerator.



